|
General Routing Failures |
| Network availability is an important and complex issue involving an assortment of features. This article looks at ways to recover from router hardware and software failures. |
Cisco supports a number of methods for recovering from router hardware and software failures.
Hardware failures both internal and external to the router can cause a router to fail. External failures, obviously, include total loss of electrical power. Internal failures involve a problem with the internal low-voltage power converters.
The most basic fault protection method is to have redundant power supplies. By this, I mean internal router power supplies. Highly available systems still need uninterruptible power supplies (UPSs), and, for longer operation, backup power such as a diesel generator. Carrier facilities, including collocation areas when appropriately contracted, have massive 48 VDC battery and generator systems.
When you determine your needs for power backup, do consider critical backup, such as cooling, lighting, and power for auxiliary devices such as modems and consoles.
On larger routers, such as the 7000/7500 and up, there are slots for two slide-in power supplies, either of which can handle full load. Smaller routers, such as the 2600, have a connector on the chassis that connects to an external power supply.
The basic modes of route processor failover are high system availability (HSA), which is specific to the 7500, and route processor redundancy (RPR). The first reboots the backup RP in the event of a failure. RPR is already configured with the startup configuration but is in a standby mode, so it does not suffer as much failover delay as HSA. Both these modes force the line cards to reset.
More advanced modes include RPR+ and stateful switchover. In RPR+, the running, not just startup, configuration is synchronized between the primary and backup RP. Some changes, such as online insertion and removal, are propagated, but not all interface card and state information. On some configurations of the 7500 and all 10000 and 12000 platforms, the line cards do not need a complete reset, although 7500s with more than two non-VIP line cards will force a reset on all cards.
Stateful switchover (SSO) implements true hot standby, with full synchronization of state and line card status. SSO is a prerequisite to nonstop forwarding (NSF).
In hierarchical routing problems, one of the first software problems to consider is how to recover from a partition in an area.

Figure 25. Generic Partitioned Area
Figure 25 shows a typical nonbackbone area in a hierarchical routing system. The dotted line down the center denotes an administrative boundary inside the area, where, for example, addresses from one subblock might be assigned to the left half and addresses from a different subblock to the right half.
Virtual links are specific to OSPF. Originally, they were developed to connect areas to area 0.0.0.0 where no physical link could be run, but they have taken on even more importance in partition repair. They allow a partitioned area 0.0.0.0 to be reconnected through a nonzero area that has two interfaces to area 0.0.0.0.
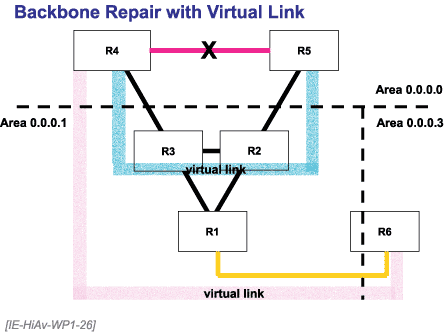
Figure 26. Backbone Repair with Virtual Link
It is more difficult to recover from partitioned nonzero areas if those areas do too much summarization into the backbone. Assume that area 0.0.0.1 has the address block 192.168.0.0/23 assigned to it, as well as 192.168.254.128/23. The latter is meant for intra-area serial links.

Figure 27. Excessive Summarization Preparing the Stage for Failure
If link 192.168.3.0/30 fails, and both R1 and R2 are advertising the summary 192.168.0.0/23 into area 0.0.0.0, how can the backbone know where to send traffic for 192.168.1.11?

Figure 28. Blackholing as a Result of Excessive Summarization
Especially for dial backup, static routes are a common recovery technique. Floating static routes are less preferred (due to a high administrative distance) than dynamic routing. They are selected when the routing protocol fails.
Alternatively, for traffic engineering or other purposes, you might use static routes to describe the preferred path, but use dynamic routing as a backup. See Figure 29.

Figure 29. OSPF Traffic Engineering Workaround
One way to recover from a partitioned nonzero area, assuming two ABRs, is to tunnel through area 0.0.0.0. As with the traffic engineering example, create a tunnel made up of static routes that are not redistributed into the dynamic routing protocol, and place that tunnel in the nonzero area.
Another application of tunneling in recovery is to tunnel through a routing domain of a different type or process.

Figure 30. Tunneling through Heterogeneous Domains
This can be an alternative for both backbone and nonbackbone areas.
[IE-HiAv-WP1-F04]
[2003-04-28-01]
|